Datenextraktion
warc2corpus
Die in diesem Projekt verwendeten Werkzeuge Archives Unleashed Toolkit (AUT) bzw. Archive Spark bieten Methoden zur Analyse von Webarchiven auf dem neuesten Stand. Beide Projekte beinhalten Funktionen um auf einfache Weise die Metainformationen eines Webarchives zu extrahieren, WARC records (Einträge) zu filtern, Verlinkungen zwischen Einträgen zu analysieren, die Einträge nach ihrem Typ zu quantisieren und Inhalte aus HTML Seiten in Textform zu extrahieren.
Speziell bei der Extraktion von Text aus HTML Seiten ist zu beachten, dass die Ergebnisse irrelevante, unerwünschte Textteile, sog. “Boilerplate” Text, enthalten. Diese Textteile stammen aus Navigationselementen, Kopf- und Fußzeilen usw. Bei der textbasierten Analyse von Webseiten können solche Fragmente die Ergebnisse verzerren und müssen daher entfernt werden. Die oben genannten Werkzeuge erlauben eine einfache und vollständige Extraktion aller Textinhalte aus einer Webseite. Diese Art der Extraktion ist für unsere Zwecke aber unzureichend, da in den Ergebnissen auch sämtliche unerwünschten Textteile enthalten sind. AUT implementiert ein brauchbareres Verfahren zur Textextraktion, den sog. “Boilerpipe” Algorithmus 1, der unerwünschte Textteile bei der Extraktion automatisiert entfernen soll. Der Algorithmus basiert auf einer Heuristik und erfordert keine Parameter. Allerdings werden nicht zuverlässig alle “Boilerplate” Textteile entfernt. Vielmehr treten in den Ergebnisse sog. false positives und false negatives auf, d.h. Textfragmente die Teil der Ergebnismenge sein sollen werden entfernt und Textfragmente die entfernt werden sollen sind in der Ergebnismenge enthalten.
Abgesehen von der inherenten Fehlerrate liefern die beiden genannten Verfahren zur Extraktion von Textinhalten aus Webseiten Fließtext.
Die im Projekt durchgeführte Analyse von Textinhalten aus online publizierten Zeitungsartikeln im Zeitverlauf benötigt als Eingabe aber sog. Webfragmente 2, d.h. Artikeltexte die mit dem Datum ihrer Publikation versehen wurden.
Hier ergeben sich folgende Probleme: um unerwünschte Textinhalte zu entfernen wird der Boilerplate Algorithmus in AUT verwendet.
Da dieser Algorithmus eine inherente Fehlerrate besitzt, kann es passieren, dass das Publikationsdatum bei der Extraktion schlichtweg entfernt wird.
Weiters kann ein extrahierter Fließtext mehrere Datumsangaben enthalten.
Das Datumsformat und die Position im Text alleine reichen dann nicht aus um festzustellen, welche der Datumsangaben das Publikationsdatum des Artikels darstellt.
Für diese Bestimmung werden vielmehr strukturelle und visuelle Informationen aus der zugrundeliegenden HTML Seite benötigt - die aber im Fließtext nicht mehr verfügbar sind.
Zum Beispiel kann das Publikationsdatum eines Artikels oftmals daran erkannt werden, dass es von einem sog. <time> Tag umschlossen wird, während andere Datumsangaben im Artikeltext nicht in HTML Tags eingerahmt werden.
Um diese Hindernisse zu umgehen und um mit Datumsangaben versehene Webfragmente für eine weiterführende Analyse im Zeitverlauf extrahieren zu können, wurde im Projekt ein Werkzeug entwickelt, das unseren Anforderungen gerecht wird: warc2corpus (w2c)3.
Funktionsweise von warc2corpus (w2c)
In w2c werden CSS Selektoren4 verwendet, um in einer HTML Seite gezielt gewünschte Element zu indizieren und zu extrahieren. Bei der Extraktion von Elementen sind neben Textinhalten auch Metainformationen wie CSS Klassen, IDs, Elementattribute etc. verfügbar. Diese Metainformationen würden bei einer Extraktion von reinem Fließtext mit bestehenden Ansätzen verloren gehen, sind aber oftmals essentiell um z.B. feststellen zu können welche Datumsangabe in einem Artikeltext das Publikationsdatum darstellt.
Webfragmente müssen per Definition neben dem Artikeltext zumind. das Datum der Publikation enthalten. Darüber hinaus erlaubt w2c die Definition von beliebigen weiteren Feldern durch Angabe von entsprechenden CSS Selektoren. Jeder so definierte Extraktor generiert bei der Extraktion einer Webseite einen entsprechenden Eintrag, zB. Artikeltext, Datum der Publikation, AutorIn.
Die Konfiguration von Extraktoren erfordert es also, CSS Selektoren für die zu indizierenden HTML Elemente einer Webseite zu definieren. Dabei erweisen sich die web developer tools von gängigen Browsern als hilfreich, wie in Abb. 1 dargestellt.
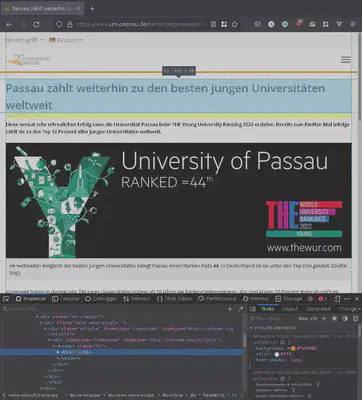
Bei der Extraktion einer Webseite wird schließlich ein Extraktor an w2c übergeben. Das generierte Resultat wird im JSON Format zurückgegeben, s. Abb. 2.
// Extraktor
{
"name": "title",
"css_path": ".news .article header.h1 h1"
}
// extrahiertes Resultat
{
"name": "title",
"value": "Passau zählt weiterhin zu den besten jungen Universitäten weltweit",
"css_path": ".news .article header.h1 h1",
"url": "https://www.uni-passau.de/bereiche/presse/[...]"
}
Neben dem CSS Selektor kann ein Extraktor eine Transformationsfunktion enthalten, mit Hilfe derer z.B. aus verschiedenen Zeitungsartikeln extrahierte Datumsangaben in ein einheitliches Format gebracht werden können.
Angenommen, in Webseite A werden Datumsangaben im Format "14. Februar 2018" gemacht, in Webseite B wird das Format "14. 2. 18" verwendet.
Mit Hilfe einer Transformationsfunktion werden beide Werte in ISO 8601 konvertiert.
Das Resultat der Extraktion durch w2c enthält dann sämtliche Datumswerte im Format "2018-02-14".
Versionen und Varianten von Webseiten in WARC Archiven
Es hat sich gezeigt, dass in WARC Archiven, welche durch Crawling über einen längeren Zeitraum erstellt wurden, Webseiten ihr Aussehen verändern und somit im Archiv in unterschiedlichen Versionen existieren. Ebenso kann ein WARC Archiv mehrere Varianten der gleichen Webseite enthalten, die an verschiedene Clients, wie mobile Geräte oder Desktop browser angepasst sind. Sowohl bei unterschiedlichen Versionen einer Webseite als auch bei unterschiedlichen Varianten bleiben die Textinhalte die gleichen, lediglich das zugrundeliegende HTML Markup verändert sich.
Für jede Variante und für jede Version einer Webseite muss in w2c ein eigener Extraktor erstellt werden, so dass für eine Webseite A mehrere Extraktoren E1, … En definiert sind.
Bei der Extraktion muss dann der passende Extraktor ausgewählt werden.
In diesem Projekt wurde dazu zuerst die URL der zu extrahierenden Seite inspiziert, zB. example.com/v1/news/123.
Aus manchen URLs, wie zB. example.com?page=123, geht nicht hervor welche Version oder welche Variante der Webseite sich dahinter verbirgt und welcher Extraktor auszuwählen ist.
In diesen Fall wurde das HTML Markup untersucht, zB. nach Tags wie <article class="mobile">, die nur an mobile Clients gesendet werden.
Auf diese Art und Weise konnte für jede Webseite in einem WARC Archiv ein passender Extraktor ausgewählt werden, um alle gewünschten Webseiten zu extrahieren.
Schließlich wurde w2c in AUT integriert und kann so effizient auf große WARC Dateien angewendet werden. Für Details zu w2c wird auf das Github Repositorium verwiesen.
-
Boilerpipe ist eine Python Bibliothek und verwendet eine Heuristik zur Entfernung von “Boilerplate” Text. Die Bibliothek wurde in das Archives Unleashed Toolkit (AUT) integriert. Die Implementierung basiert auf Kohlschütter, Christian, Peter Frankhauser, und Wolfgang Nejdl. „Boilerplate Detection using Shallow Text Features“. Vortrag auf WSDM 2010 - The Third ACM International Conference on Web Search and Data Mining New York City, NY USA. New York City, NY USA, 2010. https://www.l3s.de/~kohlschuetter/publications/wsdm187-kohlschuetter.pdf. ↩︎
-
“A Web fragment is a coherent set of textual, audiovisual or animated contents extracted from a Web page and understandable on its own. It can be a meaningful object like a post inside a forum, a news article, or a comment, and it has the particularity to be indexed by its edition date (the time when it was written). We assume that an original edition date will always be more historically accurate than the download date of the parent archived Web page.” Quentin Lobbé. Revealing Historical Events out of Web Archives. 22nd International Conference on Theory and Practice of Digital Libraries (TPDL 2018), Sep 2018, Porto, Portugal. hal-01895951 ↩︎
-
warc2corpus ist auf Github frei verfügbar, https://github.com/sepastian/warc2corpus. ↩︎