Bestandskuratierung
Linkanalyse für Bestandsausbau
Computerunterstützung beim Ausbau von Webarchivsammlungen
Die intellektuelle Auswahl archivierungswürdiger Websites für kuratierte Sammlungen setzt viel Zeit und Expertenwissen voraus.1 Im Rahmen des DFG-Projekts zur Anwendung von Methoden der Digital Humanities auf Webarchive wurde untersucht, wie dieser ressourcenintensive Auswahlprozess durch digitale Methoden unterstützt werden kann.
Das prototypisch umgesetzte Verfahren soll dabei die charakteristischen gesetzlichen Rahmenbedingungen der selektiven Webarchivierung an deutschen Gedächtnisorganisationen berücksichtigen. Da Websites aufgrund des geltenden Urheberrechts nicht ohne Genehmigung gecrawlt werden dürfen (Ausnahme bilden nur Einrichtungen mit Pflichtexemplargesetz o.ä. Regelungen), wurde ein Verfahren konzipiert, das nur auf bereits archivierten Websites aufsetzt und davon ausgehend weitere inhaltlich relevante Websites vorschlägt. Zu diesem Zweck werden aus einer bestehenden Webarchivsammlung die ausgehenden Links und ihr textueller Kontext extrahiert und so aufbereitet, dass Kurator*innen in dieser Datenbasis gezielt nach weiteren Websites zum Thema der Sammlung suchen können.
Der Auswahlprozess läuft damit nicht vollständig automatisch ab, sondern bezieht Kurator*innen aktiv ein. Sie entscheiden schließlich, welche Websites in die Sammlung aufgenommen werden sollen. Neben der inhaltlichen Relevanz können so weitere Kriterien wie der wissenschaftliche Nutzen in die Entscheidung einbezogen werden.
Suche im Linkkontext
Für die Aufbereitung des Linkkontexts werden zwei verschiedene Verfahren verwendet: Die Volltextsuche mit der Suchmaschine Apache Solr sowie die Textähnlichkeitssuche mit der Suchmaschine vespa und SentenceTransformers, einem Software-Framework, das den semantischen Gehalt von Texten mithilfe neuronaler Netzwerke erfasst. Das entwickelte prototypische Verfahren wurde anhand eines Ausschnitts der Sammlung „Bavarica“ der Bayerischen Staatsbibliothek getestet. Als prototypische Benutzeroberfläche wurden zwei Jupyter Notebooks angelegt, die in den Abbildungen 1 und 2 dargestellt sind. Die Oberfläche bietet ein Freitextfeld für die Suche im Linkkontext und zusätzlich einen Facettenfilter für die explorative Suche anhand von Schlagworten, die bei der intellektuellen Sacherschließung für die jeweilige Ausgangsseite des Links vergeben wurden. In der Ergebnisliste sind die einzelnen Links pro Domain zusammengefasst. Für jeden Link in den Suchergebnissen wird die Ziel-URL sowie der Linkkontext angezeigt, um einen ersten Eindruck von der verlinkten Ressource zu vermitteln. Im Fall der Volltextsuche sind die Suchbegriffe im Linkkontext farblich hervorgehoben. Der Quellcode zum Experiment kann auf GitHub eingesehen werden.
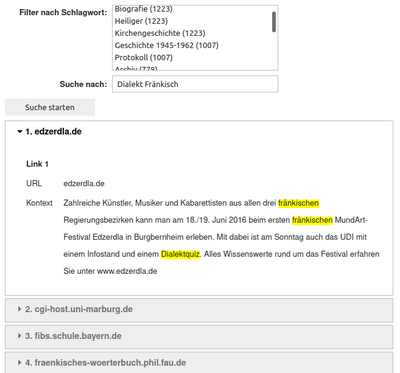
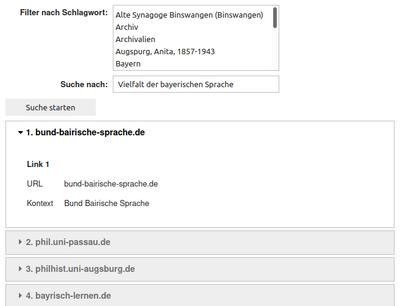
-
Zu verschiedenen Strategien zum Ausbau einer thematischen Sammlung von archivierten Websites und dem damit verbundenen Rechercheaufwand siehe z.B. Tobias Beinert, Ulf Röhrer-Ertl, und Birgit Schaefer, „Unsere Bayern im Zeitalter des Internets. Webarchive in der Bayerischen Bibliographie“, in Regionalbibliographien: Forschungsdaten und Quellen des kulturellen Gedächtnisses. Liber amicorum für Ludger Syré (Hildesheim: Georg Olms Verlag, 2019), 141–51. ↩︎