Analysen
Kollokationsnetzwerke
Der Einsatz von Keyword in Context (kwc) und Netzwerkvisualisierung
1. Politisches Framing und Keywords in Context (kwc)
In der Politikwissenschaft wird unter Framing eine Konzept verstanden, in dem die Rahmung von politischen Ideen untersucht wird. Dabei geht es unter anderem darum, wie politische Akteure über bestimmte Themen kommunizieren.
Eine Möglichkeit das Framing im Kontext der quantitativen Textanalyse zu untersuchen könnte darin liegen, den semantischen Raum um bestimmte Begriffe, im weiteren soll von Keywords gesprochen werden, zu analysieren. Neuere Methoden, die dieses leisten, sind etwa word2vec, sentence2vec oder doc2vec, die auf Vektorräumen basieren. Das Trainieren dieser neuronalen Netzwerke ist jedoch äußerst aufwendig und es wird eine große Anzahl an Text benötigt. Ist die Textmenge geringer, aber immer noch zu groß für eine qualitative Untersuchung, braucht es eine andere, feingliedrigere und vor allem robustere Methode. Eine solche Methode ist Keyword in Context (kcw).
Bei kcw werden die Wörter um ein bestimmtes Keyword herangezogen und angegeben. Dadurch wird ersichtlich, in welchem Kontext ein Wort verwendet wird. In diesem R Markdown soll diese Methode angewandt und spezifiziert werden. Die aus der kcw generierten Wörter um ein Keyword sollen als Graph dargestellt werden. Knoten sind dabei die Wörter, genauer das Keyword und die Begriffe die in der Nähe des Keywords stehen. Eine Kante zeigt die Verbindung zwischen dem Keyword und den jeweiligen Begriffen in der Nähe an. Ein solches Netzwerk ist ein ungerichteter Graph, da das gemeinsame Auftrten von Keyword und das Wort in der Nähe des Keywords keine richtungsweisende Information enthält.
Zudem sollen unterschiedliche Metadaten mit den Keywords verbunden werden, in diesem Fall sind dies die Namen der Parteien. Dadurch wird ein Netzwerk konstruiert, in dem der Kontext eines Keywords in Abhängigkeit von Parteien dargelegt wird.
Die für diese exemplarische Untersuchung herangezogenen Daten stammen aus dem DFG Projekte Methoden der Digital Humanities in Anwendung für den Aufbau und die Nutzung von Webarchiven, bei dem ein Event Crawl zum Europawahlkampf 2019 durchgeführt und Webarchive aufgebaut wurden. Die Arbeit stützt sich auf die granulare Extraktion von Inhalten aus WARC-Dateien mittels warc2corpus (siehe Artikel dazu auf dieser Webseite). Datengrundlage sind Texte bzw. Artikel der Parteienwebseiten von AFD, Bündnis 90/ Die Grünen, CDU, CSU, Die Linke, FDP, Freien Wähler, NPD, ÖDP und Piratenpartei. Nachdem auf Grundlage von warc2corpus Inhalte von WARC-Dateien extrahiert und als JSON-Dateien gespeichert wurden, sind für eine Analyse diese zunächst in ein Dataframe überführt worden. Ein Datensatz enthält Variablen wie etwa der Name der Partei, URL der gecrawlten Webpage, Text des Artikels ohne Boilerplate und einen Zeitstempel des Artikels. Da die “heiße Phase” des Wahlkampfs von Interesse ist, wird der Zeitstempel der Dokumente herangezogen, um den Untersuchungszeitraum zu definieren. Dieser ist zwischen März und Juni 2019.
Bei der Erstellung des Dataframes werden Duplikate sowie Texte exkludiert, die nur wenige Worte enthalten. Da die “heiße Phase” des Wahlkampfs von Interesse ist, wird in diesem Arbeitsschritt auf Basis des Zeitstempels der Dokumente der zu untersuchende Zeitraum definiert. Dieser ist zwischen März und Juni 2019. Der Datensatz besteht insgesamt aus 684 Datensätzen. Insgesamt besteht der Textkorpus aus 670.125 Tokens. Die Dokument-Term-Matrix enthält 2387 Tokens, die in 684 Dokumente enthalten sind.
2. Laden der Datei
library(dplyr)
df <- read.csv("data/df_german_parties_03_23_to_06_09.csv")
df$data.released_at.value <- as.Date(df$data.released_at.value)
df$data.body.value <- as.character(df$data.body.value)
df$meta.target.netloc <- as.factor(df$meta.target.netloc)
Übersicht über die Anzahl der Dokumente pro Parteiwebseite.
df$meta.target.netloc %>% summary()
## www.afd.de www.cdu.de www.csu.de
## 32 40 113
## www.die_linke.de www.die_partei.de www.fdp.de
## 160 3 93
## www.freiewaehler.eu www.gruene.de www.npd.de
## 15 67 38
## www.oedp.de www.piratenpartei.de www.spd.de
## 32 64 27
3. Teildatensätze Parteien
Es werden Teildatensätze erstellt, um später herauszufinden, ob das Keyword auf den Parteienwebeseiten unterschiedlich geframte wird.
df.afd <- df %>% filter(meta.target.netloc == "www.afd.de")
df.cdu <- df %>% filter(meta.target.netloc == "www.cdu.de")
df.csu <- df %>% filter(meta.target.netloc == "www.csu.de")
df.gruene <- df %>% filter(meta.target.netloc == "www.gruene.de")
df.afd <- df %>% filter(meta.target.netloc == "www.afd.de")
df.linke <- df %>% filter(meta.target.netloc == "www.die_linke.de ")
df.fdp <- df %>% filter(meta.target.netloc == "www.fdp.de")
df.fw<- df %>% filter(meta.target.netloc == "www.freiewaehler.eu")
df.spd<- df %>% filter(meta.target.netloc == "www.spd.de")
df.npd<- df %>% filter(meta.target.netloc == "www.npd.de")
4. Keyword in Context Methode
4.1. Textbereinigung
Zunächst wird der Text für die Analyse aufbereitet und es findet eine Textstrukturierung in Form einer Document-Term-Matrix statt. Hierfür werden folgende Methoden der Textaufbereitung angewandt:
- Entfernen von Stop-Words
- Anwendung von POS-Tagging
- Durchführung einer Lemmatisierung
Die R Packages spacy und quanteda wurden verwendet.
Für alle, die mehr zur Aufbereitung von Text erfahren möchten, liefert die Publikation von Eckl & Gahnem 2020 eine Einführung.
# Funktion: Text in Tokens umandeln & Bereinigung
spacy_text_cleaning <- function(language, dataframe, dataframe.text.col,
tokens.lemma, remove.numb,min.nchar,
collocation.min, df.col.dfm){
# language: Auswahl der Srpache -> Bsp.: "de", "en"
# dataframe: Name des dataframes -> Bsp.: df, dfx
# dataframe.text.col: Spaltenname des dataframe -> Bsp.: df$text
# tokens.lemma: Auswahl, ob Lemmatisierung durchgeführt werden soll -> Bsp.: TRUE / FALSE
# remove.numb: Auswahl, ob Nummern entfernter werden sollen -> Bsp.: TRUE / FALSE
# min.nchar: Mindestanzahl von Buchstaben in einem Wort (Dateityp numeric) -> Bsp.: 3
# collocation.min: Mindestanzahl des Aufretens von Bi-Grammen (Dateityp numeric) -> Bsp: 4
# df.col.dfm: Saplten, die als Covariablen herangezogen werden
#download spacyr for r url:https://github.com/quanteda/spacyr
library(spacyr)
library(dplyr)
library(quanteda)
# spacy_install() #needed if spacy is not install
# Initialize spaCy to call from R.
# spacy_download_langmodel("de")´
spacy_initialize(model = language, refresh_settings = TRUE)
# Tokenisierung und Text tagging (data.table wrid erstellt)
parsed <- spacy_parse(dataframe.text.col)
# Beendet den Python Prozess im Hintergrund
spacy_finalize()
# Löschen von Punktionen, Nummern, Stopwords und selbst definierte topkens
tokens <- as.tokens(parsed, use_lemma = tokens.lemma) %>%
tokens(remove_punct = TRUE, remove_numbers = remove.numb) %>%
tokens_tolower() %>%
tokens_remove(c(stopwords('de'), "vgl", "et_a1", "fiir","v0n", "a1s", "hinsichtlich",
"11nd", "z._b.", "cine", "hierzu", "erstens", "zweitens", "deutlich", "tion",
"geben", "mehr", "immer", "schon", "gehen", "sowie", "erst", "mehr", "etwa",
"dabei", "dis-", "beziehungsweise", "seit", "drei", "insbesondere", "dass", "wer",
stopwords("en")),
min_nchar = 2L, padding = TRUE)
collocation <- textstat_collocations(tokens, min_count = 2)
# Bi-Gramme
tokens <- tokens_compound(tokens, collocation, join = FALSE)
df.col.names <- c(df.col.dfm)
docvars(tokens) <- dataframe %>% select(df.col.names)
return(tokens)
}
4.2 Keyword in Context
# Funktion: Keyword in Context
keyword.in.context <- function(dataframe, dataframe.text.col, min.nchar, kwc.window, kwc.pattern){
# dataframe: Name des dataframes -> Bsp.: df, dfx
# dataframe.text.col: Splate des dataframe -> Bsp.: df$text.col
# min.nchar: Mindestanzahl von Buchstaben in einem Wort (Dateityp numeric) -> Bsp.: 3
# kwc.wondow: Anzahl der Worter vor und nach einem Keyword die berücksichtigt werden sollen
# kwc.pattern: keyword
source("functions/spacy_text_cleaning.R")
#function spacy_text_cleaning
tokens <- spacy_text_cleaning(language = "de",
dataframe = dataframe,
dataframe.text.col = dataframe.text.col,
tokens.lemma = TRUE,
remove.numb = TRUE,
min.nchar = 2,
collocation.min = 5,
df.col.dfm = c("data.body.value", "data.released_at.value", "meta.target.netloc"))
kw_immig <- kwic(tokens, pattern = kwc.pattern, window = kwc.window)
return(kw_immig)
}
Die Funktion keyword.in.context wird auf alle Texte der unterschiedlichen Parteienwebseiten angewandt.
# Auswahl des Keywords
keyword = c("EU")
kwc.afd.eu<- keyword.in.context(dataframe = df.afd,
dataframe.text.col = df.afd$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern = keyword)
kwc.cdu.eu<- keyword.in.context(dataframe = df.cdu,
dataframe.text.col = df.cdu$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern = keyword)
kwc.csu.eu<- keyword.in.context(dataframe = df.csu,
dataframe.text.col = df.csu$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern = keyword)
kwc.gruene.eu<- keyword.in.context(dataframe = df.gruene,
dataframe.text.col = df.gruene$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern =keyword)
kwc.linke.eu<- keyword.in.context(dataframe = df.linke,
dataframe.text.col = df.linke$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern = keyword)
kwc.fdp.eu<- keyword.in.context(dataframe = df.fdp,
dataframe.text.col = df.fdp$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern = keyword)
kwc.spd.eu<- keyword.in.context(dataframe = df.spd,
dataframe.text.col = df.spd$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern = keyword)
kwc.fw.eu<- keyword.in.context(dataframe = df.fw,
dataframe.text.col = df.fw$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern = keyword)
kwc.npd.eu<- keyword.in.context(dataframe = df.npd,
dataframe.text.col = df.npd$data.body.value,
min.nchar = 2,
kwc.window = 10,
kwc.pattern = keyword)
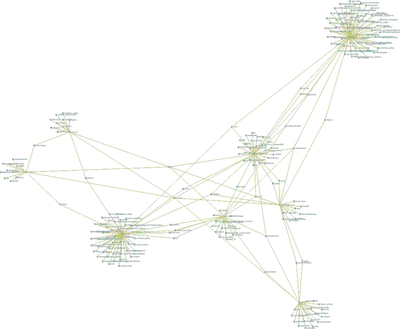
5. Datenaufbereitung & Netzwerkvisualisierung
Als nächstes findet eine Netzwerkvisualisierung der Ergebnisse statt. Hierfür müssen der Output aus der Funktion keyword.in.context zunächst aufbereitet werden. Das Netzwerk besteht aus:
- Knoten: Keywords + Meatadaten (Partei)
- Kante: Verbindung der Keywords mit den Begriffen in seiner Umgebung
- Kantengewicht: Anzahl der jeweiligen Verbindungen bzw. des gemeinsamen auftretens
# Funktion: kwc_network_data_pre
kwc_network_data_pre <- function(kwc.output, kontext.name, min.word.count){
# kwc.output: Output aus der Funktion von keyword.in.context
# kontext.name: Metadaten Information -> Bsp.: "csu" (string)
# min.word.count: Mindestanzahl eine Wortes im Fenster des Keywords
library(stringr)
kwc.output.pre <- kwc.output$pre
kwc.output.post <- kwc.output$post
kwc.keyword <- kwc.output$keyword[1]
kw <- c(kwc.output.pre, kwc.output.post)
kw2 <- str_split(kw, " ")
kw3 <- Reduce(c,kw2)
kw3 <- kw3[kw3 != ""]
df.kw <- data.frame(kw3)
df.kw2 <- df.kw %>% group_by(kw3) %>% summarise(count=n()) #column 1, column 2, edge wight
keyword <- paste0(kwc.keyword,"_",kontext.name)
df.kw2$keyword <-rep(keyword, dim(df.kw2)[1])
df.kw3 <- df.kw2 %>%
rename(V1 = kw3,
V2 =keyword,
weight = count)
df.kw4 <- df.kw3 %>% filter(weight > min.word.count)
df.kw4
}
# Funktion: kwc_network_vis
kwc_network_vis <- function(data){
library(igraph)
library(networkD3)
# Liste kwc output: 1 df, 2 character kontext name, 3 number of min wordcount
df.all = data.frame()
for (l in data) {
#function kwc_network_data_pre
df <- kwc_network_data_pre(l[[1]], l[[2]], l[[3]])
df.all <- rbind(df.all, df)
}
# Netzwerkerstellung
g = graph.data.frame(df.all[,c('V1','V2')])
E(g)$weight = df.all$weight
# Plot
p <- simpleNetwork(df.all, height="100px", width="100px",
Source = 1, # column number of source
Target = 3, # column number of target
linkDistance = 10, # distance between node. Increase this value to have more space between nodes
charge = -900, # numeric value indicating either the strength of the node
#repulsion (negative value) or attraction (positive value)
fontSize = 14, # size of the node names
fontFamily = "serif", # font og node names
linkColour = "yellow", # colour of edges, MUST be a common colour for the whole graph
nodeColour = "#69b3a2", # colour of nodes, MUST be a common colour for the whole graph
opacity = 0.9, # opacity of nodes. 0=transparent. 1=no transparency
zoom = T # Can you zoom on the figure?
)
return(p)
}
data1 <- list(kwc.afd.eu, "afd",1)
data2 <- list(kwc.cdu.eu, "cdu", 3)
data3 <- list(kwc.csu.eu, "csu", 3)
data4 <- list(kwc.gruene.eu, "gruene", 3)
data5 <- list(kwc.linke.eu, "linke", 3)
data6 <- list(kwc.fdp.eu, "fdp", 1)
data7 <- list(kwc.spd.eu, "spd", 1)
data8 <- list(kwc.npd.eu, "npd",1)
data9 <- list(kwc.fw.eu, "fw", 1)
data <- (list(data1, data2, data3, data4, data5, data6, data7, data8, data9))
p <- kwc_network_vis(data)
Das folgende Bild ist eine Vorschau. Um die interaktive Visualisierung zu öffnen, bitte hier klicken.