Bestandskuratierung
NER für Bestandserschließung
Webarchive mit NLP-Verfahren erschließen
Um ihre digitalen Bestände für Nutzer*innen zu erschließen, setzen Bibliotheken zunehmend auf die Volltextsuche. Zusätzlich experimentieren sie in den letzten Jahren mit Verfahren aus der automatischen Sprachverarbeitung (Natural Language Processing, NLP), um ihre digitalen Bestände anzureichern und Nutzer*innen bei der Sichtung und Auswertung der digitalen Daten zu unterstützen.1 Zu diesen Verfahren gehört auch die automatische Erkennung und Klassifikation von Eigennamen in Texten (Named Entity Recognition, NER). Auswertungen von Nutzungsdaten zeigen, dass Eigennamen in Suchanfragen sehr häufig vertreten sind.2 Im DFG-Projekt „Methoden der Digital Humanities in Anwendung auf Webarchive“ sollte NER deshalb zur Erschließung von Webarchivbeständen eingesetzt werden.
Technische Umsetzung
Die besten Ergebnisse im Bereich NER wurde in den letzten Jahren mit künstlichen neuronalen Netzen erzielt. Bekannte Software-Frameworks für die automatische Sprachverarbeitung wie spaCy setzen auf Netzwerkmodelle wie Convolutional Neural Networks (CNN) und seit Version 3.0 auch auf Transformer-Modelle. Die verschiedenen Software-Frameworks unterscheiden sich insbesondere dahingehend, welchen Stellenwert sie der Erkennungsleistung gegenüber der Auswertungsdauer und der benötigten Rechnerinfrastruktur einräumen. spaCy beispielsweise versteht sich als „Industriestandard“ und bietet auf Effizienz optimierte Netzwerkmodelle, deren Auswertungszeit den produktiven Einsatz auch auf CPU-Infrastrukturen ermöglicht. Andere Frameworks wie flair sind dagegen stark forschungsgetrieben und setzen GPU-Unterstützung voraus, um die Textmengen, die bei der Webarchivierung fortlaufend anfallen, in angemessener Zeit auswerten zu können. Da die Rechnerinfrastruktur für die Webarchivierung an der BSB aktuell auf CPUs basiert und eine Erweiterung auf GPUs aus Kostengründen derzeit nicht geplant ist, fiel die Wahl nach ersten Performancetests auf spaCy als Software-Framework.
Die Erkennung und Klassifikation von Eigennamen wurde in einem Python-Webdienst umgesetzt, der archivierte HTML-Dateien aus dem Containerformat WARC ausliest, ihren Inhaltstext extrahiert und entsprechend auswertet. Der NER-Dienst wurde als Auswertungsschritt in die Indexierung der Webarchivdaten eingebunden und die Ergebnisse in die Volltextsuche einbezogen.
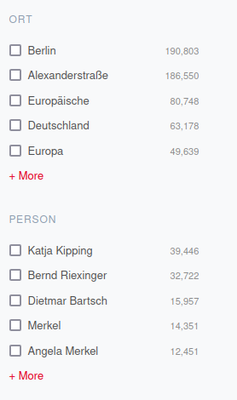
NER-Facetten in der Volltextsuche
Für Orts- und Personennamen wurde eine eigene Suchfacette eingeführt, um den Nutzer*innen einen schnellen Überblick darüber zu geben, welche Entitäten im Korpus vertreten sind. Um Trends im Korpus sichtbar zu machen, wird zusätzlich zu jedem erkannten Namen die Häufigkeit seines Vorkommens im erschlossenen Korpus angezeigt. In Kombination mit der Volltextsuche können Nutzer*innen die Filterung nach Namen beispielsweise verwenden, um zu untersuchen, welche Personen in Zusammenhang mit einem Thema genannt werden.
Insbesondere für politikwissenschaftliche Fragestellungen könnten auch Namen von Regierungseinrichtungen oder politischen Organisationen als eigene Facette sinnvoll sein. Das hier verwendete spaCy-Modell, das auf den GermEval 2014 Daten trainiert wurde, erzielt jedoch bei Orts- und Personennamen eine deutlich höhere Genauigkeit als bei Namen von Organisationen. Dieses Verhalten wurde auch bei anderen Modellen beobachtet, die im Rahmen von GermEval 2014 entwickelt wurden. Die Ursache dafür könnte einerseits in den Trainingsdaten liegen, in denen Namen von Organisationen deutlich seltener vorkommen, oder aber in der Art der Organisationsnamen, die weniger einheitlich sind als Orts- oder Personennamen.3 Abhängig von der Bedeutung der Kategorien für die spezielle Sammlung und die Nutzer*innengruppe kann es sinnvoll sein, hier mehr Aufwand in die Optimierung der Modelle zu investieren, indem Auszüge aus den eigenen Datensätzen manuell annotiert und zusätzlich als Trainingsdaten genutzt werden.
Ergebnisse und Ausblick
Die Facetten mit Orts- und Personennamen können einen schnellen Überblick darüber vermitteln, welche Politiker*innen, Regionen oder Länder im Zusammenhang mit einem Thema genannt werden. Im Prototyp hat sich jedoch als problematisch erwiesen, dass einige der erkannten Namen aus Bestandteilen der Webseite stammen, die nicht zum eigentlichen Inhaltstext gehören und standardmäßig auf jeder Seite eingebunden werden. So taucht beispielsweise die „Alexanderstraße“ als Ortsname im Zusammenhang mit dem Suchbegriff „Inklusion“ häufig auf, weil die Adresse im Footer der Website der Partei „Die Linke“ enthalten ist. Im nächsten Schritt sollten darum Verfahren evaluiert werden, um diese Seitenbestandteile automatisch zu erkennen und von der Auswertung auszuschließen. Einen möglichen Ansatz bietet die Boilerpipe-Bibliothek, die sogenannte Boilerplate-Inhalte anhand oberflächlicher Textmerkmale wie der Linkdichte zu erkennen versucht.
Fehler bei der automatischen Erkennung und Klassifikation sind nicht vollständig vermeidbar. Eine große Anzahl von Fehlern führt jedoch dazu, dass die Filteroption unbrauchbar wird, weil nicht alle Namensnennungen erkannt und angezeigt werden oder viele fälschlicherweise als Eigenname erkannten Einträge in der Suchfacette die korrekten Einträge in den Hintergrund drängen. Um die Erkennungsqualität der Modelle zu überprüfen, müssen eigene, manuell annotierte Testdatensets erstellt werden, die die auszuwertenden Daten möglichst gut abbilden. Fehlerhafte Einträge in den Suchfacetten müssen systematisch ausgewertet werden, um Schwachstellen beim Parsen des HTML-Markups, der Boilerplate-Erkennung oder den NER-Modellen zu identifizieren. Durch die manuelle Korrektur fehlerhafter Beispiele können neue Trainingsdaten gewonnen werden, um die eingesetzten Netzwerkmodelle nachzutrainieren und zu verbessern.
Der Prototyp zeigt, dass der Nutzen der Namensfacetten stark davon abhängt, wie eindeutig die Einträge sind. Namen können mehrdeutig sein, so unterscheidet beispielsweise der Eintrag „Weber“ bei den Personennamen nicht zwischen dem gleichnamigen CSU-Politiker und dem Mitglied der Bundesprogrammkommission der ÖDP. Erschwerend hinzu kommen verschiedene Namensformen, die sich auf dieselbe Person oder denselben Ort beziehen. Als weiterer Schritt nach der Namenserkennung und -kategorisierung sollten deshalb Methoden zur Disambiguierung der Namen untersucht und auf ihre Praxistauglichkeit geprüft werden. Einen Lösungsansatz bietet das sogenannte Named Entity Linking (NEL), bei dem Namen einer Entität in einer Wissensbasis zugeordnet werden. Auf diese Weise können Mehrdeutigkeiten unter Einbeziehung des Kontexts aufgelöst und verschiedene Namensvarianten aufeinander abgebildet werden.
-
Ehrmann, Maud, Estelle Bunout, und Marten Düring. „Historical Newspaper User Interfaces: A Review“. Vortrag auf IFLA WLIC 2019 - Athens, Greece - Libraries: dialogue for change. Athen, Griechenland, 2019. http://library.ifla.org/id/eprint/2578/. ↩︎
-
Chiron, Guillaume, Antoine Doucet, Mickaël Coustaty, Muriel Visani, und Jean-Philippe Moreux. „Impact of OCR Errors on the Use of Digital Libraries: Towards a Better Access to Information“. In Proceedings of the 17th ACM/IEEE Joint Conference on Digital Libraries, 249–252. JCDL ’17. IEEE Press, 2017. ↩︎
-
Benikova, Darina, Chris Biemann, Max Kisselew, und Sebastian Padó. „GermEval 2014 Named Entity Recognition Shared Task: Companion Paper“. In Proceedings of the KONVENS GermEval Shared Task on Named Entity Recognition, Hildesheim, Germany, 104–12. Hildesheim, Germany, 2014. https://www.inf.uni-hamburg.de/en/inst/ab/lt/publications/2014-benikovaetal-germeval2014.pdf. ↩︎