Analysen
Topic Modelling
Analyse eines Webarchivs zur Europawahl 2019
1. Einleitung
Das folgende R Markdwon zeigt eine inhaltliche Analyse von deutschen Parteienwebseiten. Diese wurden im Rahmen des DFG Projektes Methoden der Digital Humanities in Anwendung für den Aufbau und die Nutzung von Webarchiven gecrawlt und in ein Webarchiv überführt. Ziel dieser Analyse ist, zentrale Themen dieser Webseiten zum Wahlkampf der Europawahl 2019 explorativ zu ermitteln. Hierfür kommt die Topic Modeling Methode Latent Dirichlet Allocation von Blei et al. (2003) zum Einsatz, mit der große Textcopora untersucht werden können. Die LDA ist ein probabilistisches Modell mit dem automatisiert Wortlisten erstellt werden, die – mehr oder weniger – kohärente Themen repräsentieren. Die Arbeit stützt sich auf die granulare Extraktion von Inhalten aus WARC-Dateien mittels warc2corpus (siehe Artikel dazu auf dieser Webseite). Für eine Integration von Kovariablen in das Topic Modeling, wie etwa Zeitangaben oder Parteien, wurde auf das R Package Structural Topic Modeling von Roberts et al. (2018) zurückgegriffen.
2. Benötigte Packages
library(dplyr)
library(tidyr)
library(ggplot2)
library(scales)
library(magrittr)
library(stm)
library(stringr)
library(DT)
library(sna)
library(ggrepel)
3. Datenaufbereitung
Datengrundlage sind Texte bzw. Artikel der Parteienwebseiten von AFD, Bündnis 90/ Die Grünen, CDU, CSU, Die Linke, FDP, Freien Wähler, NPD, ÖDP und Piratenpartei. Nachdem auf Grundlage von warc2corpus Inhalte von WARC-Dateien extrahiert und als JSON-Dateien gespeichert wurden, sind für eine Analyse diese zunächst in ein Dataframe überführt worden. Ein Datensatz enthält Variablen wie etwa der Name der Partei, URL der gecrawlten Webpage, Text des Artikels ohne Boilerplate und einen Zeitstempel des Artikels.
3.1. Erstellung eines Dataframes
Bei der Erstellung des Dataframes werden Duplikate sowie Texte exkludiert, die nur wenige Worte enthalten. Da die “heiße Phase” des Wahlkampfs von Interesse ist, wird in diesem Arbeitsschritt auf Basis des Zeitstempels der Dokumente der zu untersuchende Zeitraum definiert. Dieser ist zwischen März und Juni 2019. Der Datensatz besteht insgesamt aus 681 Datensätzen.
# Umwandlung von json zu einem dataframe
filenames <- c(list.files("data/parteien_deutsch/", pattern="*.json", full.names=TRUE) )
df.list <- list()
for (f in filenames) {
# json file laden und Transformation in ein dataframe
print(f)
json = jsonlite::stream_in(file(f))
df = jsonlite::flatten(json)
# Filterung and Variablenauswahl für das dataframe
# Änderung des Datentyps
df$data.released_at.value <- as.Date(df$data.released_at.value)
df$data.body.size <- sapply(strsplit(df$data.body.value, " "), length)
# Doppelte Werte entfernen & auswahl der notwendigen Variablen
df2 <- df %>%
distinct(data.body.value, .keep_all = TRUE) %>%
filter(data.body.size > 150) %>%
filter(!is.na(data.released_at.value)) %>%
filter(data.released_at.value >= "2019-03-23" & data.released_at.value <= "2019-06-09") %>%
select(meta.name, meta.issuer,meta.type,meta.created_at,
data.released_at.value, meta.target.netloc,
data.title.value, data.body.value)
# Speicherung der dataframes in eine Liste
df.list[[f]] <- df2
}
# Zusammenführung aller dataframes
df <- merge_recurse(df.list)
df$meta.target.netloc[df$meta.target.netloc == "npd.de"] <- "www.npd.de"
df$meta.target.netloc[df$meta.target.netloc == "www.die-linke.de"] <- "www.die_linke.de "
df$meta.target.netloc[df$meta.target.netloc == "www.die-partei.de"] <- "www.die_partei.de"
# In CSV abspeichern
write.csv(df, "output_data/df_german_parties_03_23_to_06_09.csv")
3.2. Textaufbereitung
Bevor Methoden des Topic Modelings angewandt werden können, braucht es eine Textbereinigung sowie Textstrukturierung in Form einer Document-Term-Matrix. Im folgenden werden folgende Methoden der Textaufbereitung angewandt:
- Entfernen von Stop-Words
- Anwendung von POS-Tagging
- Durchführung einer Lemmatisierung
Im folgenden wurden die R Packages spacy und quanteda verwendet.
Für alle, die mehr zur Aufbereitung von Text für das Topic Modeling erfahren möchten, liefert die Publikation von Eckl & Gahnem 2020 eine Einführung.
# Funktion: Text in Tokens umandeln & Bereinigung
spacy_text_cleaning <- function(language, dataframe, dataframe.text.col,
tokens.lemma, remove.numb,min.nchar,
collocation.min, df.col.dfm){
# language: Auswahl der Srpache -> Bsp.: "de", "en"
# dataframe: Name des dataframes -> Bsp.: df, dfx
# dataframe.text.col: Spaltenname des dataframe -> Bsp.: df$text
# tokens.lemma: Auswahl, ob Lemmatisierung durchgeführt werden soll -> Bsp.: TRUE / FALSE
# remove.numb: Auswahl, ob Nummern entfernter werden sollen -> Bsp.: TRUE / FALSE
# min.nchar: Mindestanzahl von Buchstaben in einem Wort (Dateityp numeric) -> Bsp.: 3
# collocation.min: Mindestanzahl des Aufretens von Bi-Grammen (Dateityp numeric) -> Bsp: 4
# df.col.dfm: Saplten, die als Covariablen herangezogen werden
# download spacyr for r url:https://github.com/quanteda/spacyr
library(spacyr)
library(dplyr)
library(quanteda)
# spacy_install()
# Initialize spaCy to call from R.
spacy_download_langmodel("de")
spacy_initialize(model = language, refresh_settings = TRUE)
# Tokenisierung und Text tagging (data.table wrid erstellt)
parsed <- spacy_parse(dataframe.text.col)
# Beendet den Python Prozess im Hintergrund
spacy_finalize()
# Löschen von Punktionen, Nummern, Stopwords und selbst definierte topkens
tokens <- as.tokens(parsed, use_lemma = tokens.lemma) %>%
tokens(remove_punct = TRUE, remove_numbers = remove.numb) %>%
tokens_tolower() %>%
tokens_remove(c(stopwords('de'), "vgl", "et_a1", "fiir","v0n", "a1s", "hinsichtlich",
"11nd", "z._b.", "cine", "hierzu", "erstens", "zweitens", "deutlich", "tion",
"geben", "mehr", "immer", "schon", "gehen", "sowie", "erst", "mehr", "etwa",
"dabei", "dis-", "beziehungsweise", "seit", "drei", "insbesondere",
stopwords("en")),
min_nchar = 2L, padding = TRUE)
collocation <- textstat_collocations(tokens, min_count = 30)
# Bi-Gramme
tokens <- tokens_compound(tokens, collocation, join = FALSE)
df.col.names <- c(df.col.dfm)
docvars(tokens) <- dataframe %>% select(df.col.names)
return(tokens)
}
# Funktion: spacy_text_cleaning
tokens <- spacy_text_cleaning(language = "de",
dataframe = df,
dataframe.text.col = df$data.body.value,
tokens.lemma = TRUE,
remove.numb = TRUE,
min.nchar = 2,
collocation.min = 5,
df.col.dfm = c("data.body.value", "data.released_at.value", "meta.target.netloc"))
# Erstellung einer Dokument-Term-Matrix
dfm_parties <- tokens %>%
dfm() %>%
dfm_select(min_nchar = 2L) %>%
dfm_trim(min_docfreq = 10) %>%
dfm_trim(max_docfreq = 0.5,
docfreq_type = 'prop')
Insgesamt besteht der Textkorpus aus 670.125 Tokens. Die Dokument-Term-Matrix enthält 2387 Tokens, die in 684 Dokumente enthalten sind.
3.3. Das Textkorpus
dim(dfm_parties)
df_sum_tokens <- as.data.frame(summary(tokens))
df_sum_tokens$meta.target.netloc <- dfm_parties@docvars$meta.target.netloc
df_sum_tokens %>%
group_by(meta.target.netloc) %>%
summarise(Count_tokens = sum(as.numeric(Freq)))
4. Structural Topic Modeling - STM
Im nun folgenden Schritt soll das Topic Modeling durchgeführt werden. Dabei wird auf das R Package STM zurückgegriffen.
4.1. Evaluation der Topicanzahl
Neben der Textaufbereitung gibt es unerschiedliche Variablen, die einen Einfluss auf die Güte der Topics in einem Modell haben. Besonders hervorzuheben ist dabei die Anzahl der Topics. Um eine optimale Topicanzahl zu bestimmen, gibt es verschiedene Methoden der Evaluation (Blei et al. 2003), (Mimno et al. 2011), (Roberts et al. 2014). Im Zusammenhang mit unserer Fallstudie beziehen wir uns auf den Ansatz von Roberts et al. (2014), die zwei Metriken verwenden. Erstens verwenden wir das Kohärenzmaß von Mimno (2011), das misst, wie kohärent die Wörter in einem Thema sind. Zweitens verwenden wir das Exklusivitätsmaß von (Bischof und Airoldi (2012), das bestimmt, wie exklusiv die Topics sind. Der Wert ist für ein Topic umso höher, je mehr Wörter es enthält, die aber nicht in anderen Topics vorkommen. Die Kohärenz der Topics nimmt mit zunehmender Exklusivität ab. Ein Modell hat also eine optimale Anzahl von Topics, wenn beide Werte relativ hoch sind. Die Bewertung sollte sich aber nicht nur auf die beiden Metriken stützen. Eine intellektuelle Prüfung mehrerer Modelle bzw. deren Themen ist ebenso wichtig. Auf diese Weise können die Ergebnisse verschiedener Modelle miteinander verglichen werden. Am Ende wird das Modell verwendet, das die meisten eindeutig interpretierbaren Themen enthält.
# Funktion: Evaluation STM Model
# Semantic Coherence & Exclusivity
evaluation_stm <- function(dfm, n.topics){
# dfm: document frequecy martrix
# n.topics: Anzahl an Topics in einem Vektor die miteinander verglichen werden sollen -> Bsp.: epample <- c(10, 20, 49, 89)
library(quanteda)
library(stm)
library(ggplot2)
library(dplyr)
dfm2stm <- convert(dfm, to = "stm")
# Berechnung unterschiedlicher Modelle
kResult <- searchK(dfm2stm$documents, dfm2stm$vocab, K=n.topics, data=dfm2stm$meta)
### Semantic Coherence & Exclusivity
# Erstellung eines dataframes mit den Ergebnissen
semantic_coherence <- kResult$results$semcoh
exclusivity <- kResult$results$exclus
topic_model <- kResult$results$K
n_topics = c()
for (i in n.topics){
n_topics = c(n_topics, paste(i, "Topics", sep = " "))
}
evaluation_var <-data.frame(exclusivity,semantic_coherence, topic_model, n_topics)
# Plot
px <- ggplot(evaluation_var, aes(semantic_coherence, exclusivity)) +
geom_point(color = 'red')+
geom_label_repel(aes(label = n_topics, fill = factor(n_topics)), color = 'white',size = 2.5) +
theme(legend.position = "bottom") +
labs(title="Models evaluation: Semantic coherence and exclusivity",
x = "semantic coherence",
y = " exclusivity") +
labs(fill = "Modelle mit ") +
theme_update(plot.title = element_text(hjust = 0.5))
px
return(list(graph = px, df.evaluation = evaluation_var))
}
evaluation.list <- evaluation_stm(dfm = dfm_parties, n.topics = c(10, 20, 30, 40, 50, 60, 70, 80, 90, 100) )
plot.graph <- evaluation.list$graph
plot.graph
ggsave("evaluation_stm_modell_sm_excl.png", width = 20, height = 10, units = "cm", dpi = 300)
df.evaluation <- evaluation.list$df.evaluation
write.csv(df.evaluation, "output_data/df_evaluation_topics_german_parties_03_23_to_06_09.csv")
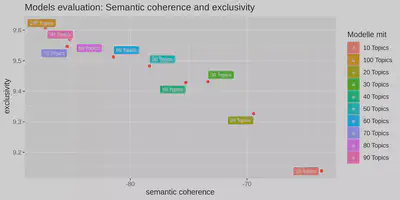
4.2. Modell mit 50 Topics
Die Ergebnisse zeigen, dass ein Modell mit 50 Topics optimal hinsichtlich beider Metriken ist.
# Überführung von einer Dokument-Term-Matrix zu einer Document-Frequency-Martix (STM)
dfm2stm <- convert(dfm_parties, to = "stm")
topic.count <- 50
model.stm <- stm(dfm2stm$documents,
dfm2stm$vocab,
K = topic.count,
data = dfm2stm$meta,
init.type = "Spectral") # (vgl. Arora et al. 2014 - sehr schneller Algorithmus)
save.image('output_data/web_archive_eu_election_tokens_enger_zeitraum_23_03.RData')
4.3. Wortlisten der Topics
Die folgende Tabelle zeigt die Wortlisten bzw. die zehn am stärksten gewichteten Wörter für die jeweiligen Topics.
load('output_data/web_archive_eu_election_tokens_enger_zeitraum_23_03.RData')
library(rmarkdown)
library(stm)
library(dplyr)
Hier fehlt die Tabelle im MD Format
4.4. Labels für die Topics
Für jedes Topic wird ein Label vergeben. Topics, deren Inhalte nicht interpretiert werden können, erhalten ein “_xxx”. Im weiteren Verlauf der Analyse sollen sie nicht mehr berücksichtigt werden.
4.5. Topic labels
topic.id <- c(seq(1,50,1))
topic.label <- c("Party: Freie Wähler",
"präsidium_xxx",
"East-West (Germany)",
"Facebook Giegold",
"bundesparteitag_xxx",
"Security policy Bavaria",
"Weber & European Policies ",
"Söder, Taxes & Redistributive Policies",
"fw_xxx",
"million_xxx", #10
"Economic Policy & Altmeier",
"namen_wahl_xxx",
"wahl_xxx",
"Hungary & Rule of Law ",
"Trade Unions & Left",
"FDP & Liberalism",
"Gender & Feminism",
"hermann_xxx",
"relevant_xxx",
"Data Retention & Piratenpartei", #20
"Basic Law, Volk & Gauland",
"Copyright Law & Upload Filter",
"grüne_xxx",
"Arms Export & War",
"Affordable Housing",
"Ecology & Habeck",
"links_xxx",
"behin_xxx",
"dfp_xxx",
"Dresden & Migration", #30
"erklärung_xxx",
"German Armed Forces",
"Precarious Employment",
"Piratenpartei & Internet",
"Coal Exit & Renewable Energies",
"stuttgart_xxx",
"einstellung_xxx",
"erinnerung_xxx",
"kurz_xxx",
"kevin_xxx", #40
"Beer European Election Campaign",
"trans_xxx",
"Brexit",
"Migration & Asyl",
"bayer_xxx",
"Species Protection & Petition for a Referendum",
"freihei_xxx",
"Minimum Wage & Employment",
"Nato & Europe",
"freund_xxx")
# Labels werden in ein dataframe abgespeichert
df.topic.labels <- as.data.frame(topic.id)
df.topic.labels$label <- topic.label
df.topic.labels$label <- as.character(df.topic.labels$label)
df.topic.labels$xxx <- str_detect(df.topic.labels$label, "_xxx")
5. Analysen & Visualisierung
Nach der Textbereinigung und -aufbereitung, der Modellevaluation und -berechnung werden nun die Ergebnisse dargelegt und visualisiert. Die dargelegten Ergebnisse dienen lediglich der Anschauung der Methoden. Die visualisierten Topics sind somit nur Beispiele. Für eine verstärkte inhaltliche Interpretation der Ergebnisse verweisen wir auf die einschlägigen Publikationen des Projekts.
5.1. Top Topics
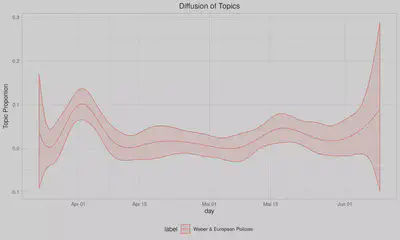
Hierfür sollen zunächst die häufigsten Topics im Korpus dargelegt werden. Dabei zeigt sich, dass die Topics Söder, Taxes & Redistributive Policies, Weber & European Policies und Dresden & Migration am häufigsten im Korpus erscheinen. Insbesondere die beiden ersten Topics sind im Kontext des Europawahlkampfes zu verstehen.
# Funktion: Plot der häufigsten Topics im Korpus
top_topics_corpus <- function(stm.theta, df.topic.labels,
n.top.topics.plot){
#stm.theta: Wahscheinlichkeit, dass ein Topic in einem Dokument enthlaten ist
#df.topic.labels: dataframe mit den Topic Labels
#n.top.topics.plot: Anzahl der Topics die in der Visualisierung berücksichtigt werden sollen
df.propotion <- as.data.frame(colSums(stm.theta/nrow(stm.theta)))
colnames(df.propotion) <- c("probability")
df.s <- cbind(df.topic.labels, df.propotion)
#Entfernen von unbrauchbaren Topics
df.s2 <- df.s %>%
filter(xxx == FALSE)
# dataframe
df.s3 <- df.s2[order(-df.s2$probability), ] %>% drop_na()
df.s3$labels <- factor(df.s3$label, levels = rev(df.s3$label))
df.s3$probability <- as.numeric(df.s3$probability)
df.s3$probability <- round(df.s3$probability, 4)
# Plot
ht <- ggplot(df.s3 %>% head(n.top.topics.plot), aes(x = labels, y = probability)) +
geom_bar(stat = "identity", width = 0.2) +
coord_flip() +
geom_text(aes(label = scales::percent(probability)), #Scale in percent
hjust = -0.25, size = 4,
position = position_dodge(width = 1),
inherit.aes = TRUE) +
ggtitle(label = paste0("Top ", n.top.topics.plot, " Topics")) +
theme(plot.title = element_text(hjust = 0.5))
return(ht)
}
top_topics_corpus(stm.theta = model.stm$theta,
df.topic.labels = df.topic.labels,
topic.del = topic.del,
n.top.topics.plot = 10)
ggsave("output_vis/top_10_topics.png", width = 40, height = 15, units = "cm", dpi = 300)

5.2. Korrelationsnetzwerk
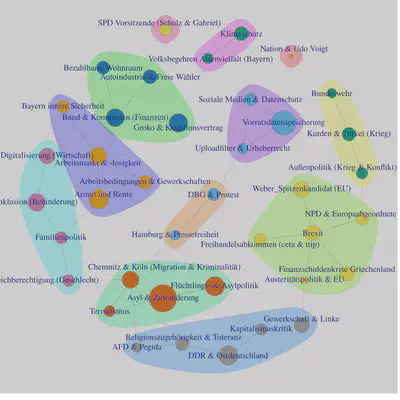
Um ein differenzierteres Bild über die Themen auf den Parteienwebseiten zu bekommen, ist es wichtig zu verstehen, in welchem Kontext die einzelnen Topics stehen und wie diese auch gemeinsam genannt werden. Die nächste Visualisierung zeigt daher ein Korrelationsnetzwerk. Die Knoten repräsentieren dabei die gelabelten Topics. Die Kanten stehen für die Wahrscheinlichkeit, dass die beiden verbundenen Topics gemeinsam in einem Dokument enthalten sind. Auf Grundlage des Modularity Algorithmus kann so ein Clustering vorgenommen werden, bei dem dirket und indirekt verbundene Knoten bzw. Topics gruppiert werden. Dadurch können unterschiedliche Themen auf einer höheren Abstraktionsebene identifiziert werden.
Ein solches thematisches Cluster ist etwa durch die miteinander verbunden Knoten bzw. Topics Soziale Medien & Datenschutz, Vorratsdatenspeicherung und Uploadfilter & Urheberrecht zu identifizieren.
# Funktion: Korrelationsnetzwerk
# Optimiert by Carsten Schwemmer: https://github.com/cschwem2er/stminsights
library(stminsights)
library(shiny)
library(shinydashboard)
library(ggraph)
library(igraph)
library(stringr)
corr_networks <- function(model.stm, df.col.topic.labels, min.correlation){
# model.stm: Das stm Modell
# df.col.topic.lable: Spalte des dataframes mit den Labels der Topics -> Bsp.: df.topics$labels
# min.correlation: Mind. Korrelation - Cutoff für die Anzeige der Kanten
stm_corrs <- get_network(model = model.stm,
method = 'simple',
labels = paste(df.topic.labels$label),
cutoff = min.correlation,
cutiso = TRUE)
df.corrs2 <- igraph::as_data_frame(stm_corrs, "both")
df.corrs2$vertices$props <- df.corrs2$vertices$props*500
stm_corrs3 <- graph_from_data_frame(df.corrs2$edges, directed = F, vertices = df.corrs2$vertices)
bad.topic <- V(stm_corrs3)$name[str_detect(V(stm_corrs3)$name, "_xxx")]
stm_corrs4 <- stm_corrs3 - c(bad.topic)
clp2 <- cluster_label_prop(stm_corrs4, weights = E(stm_corrs4)$weight)
# Plot
plot_clp2 <- plot(clp2,
stm_corrs4,
vertex.size = V(stm_corrs4)$props,
vertex.label.cex=10)
plot_clp2
#ggsave("output_vis/corr_network2.png", width = 50, height = 50, units = "cm", dpi = 300)
svg("output_vis/corr_network_moularity3.svg",width=40, height=40)
dev.off()
return(list(graph1 = graph, graph2 = stm_corrs4))
}
source("functions/correlation_topic_network.R")
networks <- corr_networks(model.stm = model.stm,
df.col.topic.labels = df.topic.labels$label,
min.correlation = 0.005)
5.3. Themenkonjunktur
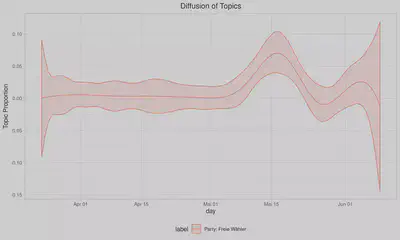
Der Vorteil von STM ist, dass auch Kovariablen in das Modell mit aufgenommen werden können. So kann etwa die zeitliche Konjunktur eines Topics dargelegt werden. Genau genommen handelt es sich hierbei um eine Polynomiale Regression, wobei die abhängige Variable die Auftrittswahrscheinlichkeit eines Topics in einem Dokument ist. Die unabhängige Variable das Publikationsdatum des Dokuments auf der Webseite.
# Funktion: Topic over time Time
topic_over_time <- function(dfm2stm, dfm2stm.meta.date, topic.count, model.stm,
df.topic.labels, topic.number.id){
# dfm2stm:
# dfm2stm.meta.date: Enthält die Zeitanageben
# topic.count: Anzahl der kalkulierten Topics
# model.stm: Das STM Modell
# df.topic.labels: Spalte des dataframes mit den Labels der Topics -> Bsp.: df.topics$labels
# topic.number.id: ID der Topics
dfm2stm <- dfm2stm
# WICHTIG: STM KANN NICHT MIT DEM DATEITYP DATE ARBEITEN !!!
dfm2stm$meta$datum <- as.numeric(dfm2stm.meta.date)
model.stm.ee <- estimateEffect(1:topic.count ~ s(datum), model.stm, meta = dfm2stm$meta)
library(stminsights)
effects <- get_effects(estimates = model.stm.ee,
variable = 'datum',
type = 'continuous')
df.topic.labels$topic <- as.factor(df.topic.labels$topic.id)
effects2 <- left_join(effects, df.topic.labels, by = "topic")
return(effects2)
}
source("functions/topic_over_time.R")
# Umwandlung der Zeitangaben von numeric zu Date
dfm2stm$meta$data.released_at.value2 <- as.Date(dfm2stm$meta$data.released_at.value, origin = "2019-03-23")
# Ordnen der Zeitangaben
dfm2stm$meta<- dfm2stm$meta[order(dfm2stm$meta$data.released_at.value),]
# Anwendung der Funktion
estimate.topic.time <- topic_over_time(dfm2stm = dfm2stm,
dfm2stm.meta.date = dfm2stm$meta$data.released_at.value2,
topic.count = 50,
model.stm = model.stm,
df.topic.labels = df.topic.labels)
estimate.topic.time$value2 <- as.Date(estimate.topic.time$value, origin = "1970-01-01")
# Funktion für die Visualisierung
plot_topic_time <- function(topic_number){
# topic_number: ID des Topics das visualisiert werden soll
p_jahr <- estimate.topic.time %>% filter(topic == topic_number) %>%
ggplot(aes(x = value2, y = proportion, color = label,
group = label, fill = label)) +
geom_line() +
geom_ribbon(aes(ymin = lower, ymax = upper), alpha = 0.2) +
theme_light() + labs(x = 'day', y = 'Topic Proportion') +
theme(legend.position = "bottom") +
ggtitle(label = paste0("Diffusion of Topics")) +
theme(plot.title = element_text(hjust = 0.5))
print(p_jahr)
}
plot_topic_time(1)
ggsave("output_vis/topic_time_1.png", width = 40, height = 15, units = "cm", dpi = 300)
plot_topic_time(7)
ggsave("output_vis/topic_time_7.png", width = 40, height = 15, units = "cm", dpi = 300)
5.4. Themen & Parteien
Zuletzt soll untersucht werden, auf welchen Parteienwebseiten ein Thema wahrscheinlich ist.
# Funktion:
topic_pref_parties <- function(dfm2stm, dfm2stm.meta.data, topic.count, model.stm,
df.topic.labels){
# dfm2stm
# dfm2stm.meta.paries: Metadaten des Modlls -> Parteiennamen
# topic.count:
# model.stm: STM Modell
# df.topic.labels: Spalte des dataframes mit den Labels der Topics -> Bsp.: df.topics$labels
# topic.number.id: Topic ID
dfm2stm <- dfm2stm
dfm2stm$meta$parties <- as.numeric(dfm2stm.meta.data)
model.stm.ee.parties <- estimateEffect(1:topic.count ~ s(parties), model.stm, meta = dfm2stm$meta)
library(stminsights)
effects <- get_effects(estimates = model.stm.ee.parties,
variable = 'parties',
type = 'pointestimate')
df.topic.labels$topic <- as.factor(df.topic.labels$topic.id)
effects2 <- left_join(effects, df.topic.labels, by = "topic")
return(effects2)
}
# Anwendung der Funktion
estimate.topic.pref.parties <- topic_pref_parties(dfm2stm = dfm2stm,
dfm2stm.meta.data = dfm2stm$meta$meta.target.netloc,
topic.count = 50,
model.stm = model.stm,
df.topic.labels = df.topic.labels)
# Funktion: Visualisierung
plot_topic_pref_parties <- function(estimate.topic.pref.parties, topic.id.number){
df.effects2 <- as.data.frame(estimate.topic.pref.parties)
df.parties <- data.frame(value = as.factor(c(1,2,3,4,5,6,7,8,9, 10, 11,12)),
parties = c("www.afd.de", "www.cdu.de", "www.csu.de", "www.die_linke.de",
"www.die_partei.de", "www.fdp.de", "www.freiewaehler.eu",
"www.gruene.de", "www.npd.de", "www.oedp.de", "www.piratenpartei.de",
"www.spd.de"))
df.effects2 <- left_join(df.effects2, df.parties, by = "value")
df.effects2.x <- df.effects2 %>%
filter(topic == topic.id.number) %>%
filter(parties != "www.die_partei.de") # option
g<- ggplot(df.effects2.x,
aes(x=parties, y=proportion, group=label)) +
geom_point(aes(size=proportion), alpha=0.52) +
geom_errorbar(width=.1, aes(ymin=lower, ymax=upper), colour="darkred") +
labs(x="Partei",y= "probability", title=paste0("Topic ", topic.id.number, ": ", df.effects2.x$label)) +
theme(axis.text.x = element_text(angle=90))
plot(g)
#ggsave(paste0("output_vis/topic_for_parties",topic.id.number,"_",df.effects2.x$label[1],".png"),
# width = 20, height = 10, units = "cm", dpi = 300)
return(g)
}
plot_topic_pref_parties(estimate.topic.pref.parties = estimate.topic.pref.parties,
topic.id.number =7)
plot_topic_pref_parties(estimate.topic.pref.parties = estimate.topic.pref.parties,
topic.id.number =8)




6. Erstellen von Teildatensätze
Durch die Auftretenswahrscheinlichkeit eines Topics in einem Dokument können Teilkorpora erstellt werden. Es lassen sich Dokumente auswählen, die eine gewisse Wahrscheinlichkeit besitzen, dass ein spezifisches Topic in ihnen enthalten ist. Die somit erzeugten Teilkorpora können je nach Größe dann ein weiteres Mal auf Grundlage von quantitativen Methoden untersucht werden. Genauso sind qualitative Analysemethoden anschlussfähig, die dann die Tiefenstruktur der Texte analysieren können.
# Function
topic_document_df <- function(model.stm, df.text, df.text.col, topic.id, procent.quantil){
# model.stm
# df.text: Text im dataframe
# df.text.col: Bsp.: df2$data.body.value
# topic.id: Topic ID
# procent.quantil: Mindeswahrscheinlichkeit für das Auftreten, Quantil
doc_topic <- findThoughts(model.stm,
texts = df.text.col,
topics =topic.id,
n = 10000,
thresh = quantile(model.stm$thet, probs = c(procent.quantil)))
df.text$index <- seq(nrow(df.text))
df <- filter(df.text, index %in% unlist(doc_topic$index))
return(df)
}
df.soeder_redistrubitive_pol <- topic_document_df(model.stm = model.stm,
df.text = df,
df.text.col = as.character(df$data.body.value),
topic.id = 8,
procent.quantil = 0.99)