Bestandskuratierung
Volltextsuche
Volltextsuche in Webarchiven
Wer im Web nach Inhalten sucht, wählt typischerweise den Einstieg über eine Suchmaschine. Sie bereitet die Masse der im Internet verfügbaren Texte so auf, dass die Daten find- und nutzbar werden. Auch für Webarchivsammlungen ist ein solcher Zugang sinnvoll. Wissenschaftler*innen, die sich beispielsweise für die Position einer Partei im Bereich Grenzpolitik interessieren, könnten so in einer Sammlung von archivierten Parteien-Websites gezielt die Dokumente ermitteln, die sich mit diesem Thema beschäftigen.
Stand der Forschung und Entwicklung
Internationale Vorreiter im Bereich der Webarchivierung wie das portugiesische Webarchiv Arquivo.pt haben diesen Bedarf erkannt und bereits ab 2010 damit begonnen, eine Volltextsuche für Webarchivdaten zu implementieren. 2014 richtete das UK Web Archive in einem Forschungsprojekt eine Volltextsuche für seine Sammlungen ein. Das warc-discovery Framework, das in dem Projekt entstanden ist und einen „warc-indexer“ zur Indexierung von Webarchivdaten in die Suchmaschine Apache Solr enthält, steht als quelloffene Software zur Verfügung.
Auf dem Index, wie ihn der warc-indexer erzeugt, können verschiedene Benutzeroberflächen aufsetzen. Die jüngste Entwicklung ist die SolrWayback des dänischen Webarchivs Netarkivet, die neben einer reinen Volltextsuche auch Exportoptionen, eine Bildersuche anhand der geographischen Koordinaten des Aufnahmeorts und verschiedene Datenvisualisierungen wie Linkgraphen anbietet.
Entwicklung im Rahmen des Projekts
Eines der Ziele des DFG-Projekts „Methoden der Digital Humanities in Anwendung auf Webarchive“ war es, die Auffindbarkeit und Nutzbarkeit von Webarchivdaten für Forschende zu verbessern. In diesem Zusammenhang wurden auch die Möglichkeiten einer Volltextsuche in Kombination mit Verfahren der automatischen Sprachverarbeitung untersucht. Dafür wurde eine prototypische Volltextsuche für ein Teilkorpus des Event-Crawls zur Europawahl 2019 eingerichtet. Das Teilkorpus umfasst alle archivierten Versionen der Websites der Kandidat*innen sowie der deutschen Parteien. Da der Datenbestand urheberrechtlich geschützt ist, kann der entstandene Prototyp nicht öffentlich zugänglich gemacht werden.
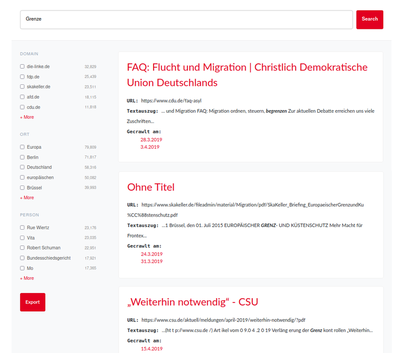
Der Fokus im Projekt liegt auf geisteswissenschaftlichen Fragestellungen und den eigentlichen Inhaltstexten einer Website, die im HTML-Markup oder Textformaten wie PDF oder Office-Dokumenten vorliegen. Unser Prototyp beschränkt sich deshalb auf Textdaten, die durch automatisch erkannte Eigennamen (Named Entity Recognition), NER angereichert wurden, um eine Filterung der Ergebnisse nach Personen- und Ortsnamen zu ermöglichen. Für die Indexierung wurde das Solr-Schema und der warc-indexer des UK Web Archive genutzt und entsprechend unserer Anforderungen modifiziert.
Da Websites im Rahmen des Event-Crawls nicht inkrementell, sondern wiederholt vollständig gecrawlt wurden, beinhaltet die Datenbasis eine hohe Zahl von Duplikaten. Um die Suchergebnisse trotzdem übersichtlich zu präsentieren, werden diese den Nutzer*innen gruppiert nach URL angezeigt. Für jede URL wird der Titel sowie ein Textauszug mit dem Suchbegriff angezeigt. Über die Liste der Crawlzeitpunkte können Nutzer*innen gezielt einzelne Versionen einer Website im Viewer aufrufen. Die Ergebnisse sind nach Relevanz sortiert, wobei das Standard-Relevanzmaß von Apache Solr (BM25) genutzt wird.
Zusätzlich zur Suche nach einzelnen Begriffen können Nutzer*innen die Ergebnisse auch anhand von Facetten filtern. In der prototypischen Umsetzung sind zunächst die Domain sowie experimentell die automatisch erkannten Orts- und Eigennamen als Facetten vorhanden. Damit Forscher*innen auf der Basis der Suche ein Korpus für weitere Auswertungen erstellen können, können sie die Metadaten der Suchergebnisse im JSON-Format exportieren. Zur eindeutigen Referenzierung der archivierten Ressourcen wurde das in der Entwicklung begriffene Persistent Web Identifier (PWID) Format aufgegriffen. Das PWID-Format eignet sich insbesondere für archivierte Ressourcen, die nicht frei im Web verfügbar sind und nicht über eine eigene URL referenziert werden können.
pwid:webarchiv-dh.digitale-sammlungen.de:2019-03-22T22:02:01.000Z:part\
:https://www.csu.de/partei/parteiarbeit/arbeitskreise\
/asp/asp-aktuell/januar-2014/\
bericht-ueber-den-vortrag-ueber-die-drohnenproblematik/
Bewertung und Ausblick
Facetten
Für das Teilkorpus zur Europawahl erwies sich vor allem die Domain-Facette als hilfreich zur Eingrenzung und Strukturierung der Ergebnisse. Durch die Filterung anhand der Domain lassen sich die Stellungnahmen verschiedener Parteien zu einem Thema einfach gegenüberstellen. Für die Zukunft wäre eine Filterung nach Crawlzeitraum sowie nach Sprache sinnvoll, um sprachlich einheitliche Korpora für die Textanalyse bilden zu können.
Die Anzahl der Treffer pro Kategorie in einer Facette ist nicht aussagekräftig, aus ihr kann beispielsweise nicht geschlossen werden, dass eine bestimmte Partei häufiger über ein bestimmtes Thema spricht als andere. Grund dafür ist die hohe Redundanz zwischen den verschiedenen Versionen einer Website und zusätzliche Duplikate, die sich aus der technischen Umsetzung der unterschiedlichen Websites ergeben.
Eine Auswertung der NER-Facetten findet sich in hier.
Darstellung der Ergebnisse
Die Gruppierung der Ergebnisse nach URL verbessert die Übersichtlichkeit nur bedingt. Verschiedene Möglichkeiten zur Deduplizierung anhand der URL mit oder ohne Berücksichtigung von Query-Strings oder anhand des Inhalts mit oder ohne Berücksichtigung kleiner Abweichungen müssten in Zukunft untersucht werden.
Medienarten
Die Datenvielfalt ist eine große Herausforderung und macht gleichzeitig den besonderen Reiz der archivierten Webdaten aus. Sie sollte in Folgeprojekten stärker erschlossen werden, wobei die SolrWayback als Vorbild dienen kann. Weiterer Verbesserungsbedarf besteht bei der Extraktion von Textinhalten aus dynamischen Websites. Websites wie Twitter fordern Seitenbestandteile je nach Bedarf vom Server im JSON-Format an. Aktuell wertet der warc-indexer diese JSON-Dateien nicht aus, sodass nachgeladene Seiteninhalte für die Volltextsuche unsichtbar sind.